oguruma
XLDnaute Impliqué
Bonjour,
Ayant eu dans un projet récent la nécessité d'identifier le TopN du nombre de flux par application et de les catégoriser en deux sortes, je vous partage les solutions que j'ai réalisé.
A vous de choisir celle qui vous convient le mieux selon la volumétrie que je n'ai pas testé.
Exemple de tableaux comportant des applications avec le nbr de flux qui ont été traités

Dans un 1er temps il a été nécessaire de déterminer le rang de chaque application comme ceci

via la formule : =EQUATION.RANG([@NbreFlux];[NbreFlux];1)
(occasion de découvrir EQUATION.RANG)
Voici le résultat pour chaque méthode

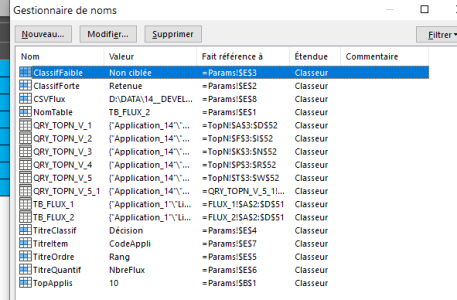
Tout cela passe par une liste de paramètres

Classification forte : Nom de la catégorie quand le rang (ordre) de l'item est dans le TopN (Top des applications) souhaité
Classification faible : Nom de la catégorie quand le rang (ordre) de l'item n'est pas dans le TopN (Top des applications) souhaité
Colonne quantification : Colonne permettant d'évaluer si le rang est dans le TopN
Colonne classification : Titre de la colonne qui va héberger la catégorie
Colonne item : Colonne de classement
Fichier CSV Flux : Nom du fichier .csv à importer en cas d'apport externe des données
Nombre d'applications à retenir pour le TopN :

pour le coup je n'ai pas utilisé de tableaux mais des noms de champs que je récupère dans PowerQuery pour les transformer à l'issue en table. Par ce biais voici une autre manière de gérer des paramètres que l'on passe à PowerQuery.
Liste des noms de champs

Environnement PowerQuery

Au premier coup d'oeil on aperçoit un début de standardisation des noms d'objets. Je me suis dit qu'il était temps de mettre cela en place depuis....mes nombreux codes en M.
La nomenclature me semble assez simple à comprendre, je passe donc sur ce point.
RECUPERATION DES NOMS DE CHAMPS
Pour chaque nom de champ le principe est le même - exemple :
Cas d'un type texte
Cas d'un type entier
Petite astuce pour regrouper les noms de paramètres commençant par PRM_ afin de les convertir dans une table TBL_PARAM
La colonne "Name" est filtrée par le préfixe PRM_ (d'où l'intérêt de standardiser les noms des objets).

Pour accéder à un paramètre une fonction fnGetParameters
Désormais nous avons donc le choix, soit récupérer un paramètre via son de variable comme PRM_STR_ClassifFaible soit en utilisant la table de paramètre TBL_PARAM et la fonction fnGetParameters comme ceci P_STR_Quantif=fnGetParameters("PRM_STR_Quantif"),
Une version 5_1 récupère les paramètres via cette table.
RECUPERATION DES SOURCES DE DONNEES : TBL_SRC_DATA_FLUX_1
Nous avons ici utilisé directement la variable PRM_STR_NomTable.
Dans toutes les solutions on remarquera la gestion dynamique des noms de colonnes et l'utilisation de Expression.Evaluate qui permet de construire un code totalement paramétrable via une feuille Excel.
Version 1
Version 2
Version 3
Version 4
Attention cette version n'affichera que les colonnes identifiées par les paramètres PRM_STR_Item, PRM_STR_Quantif, PRM_STR_Classif
Version 5
Version 5_1 avec la table des paramètres
Dans ce code comme les autres on remarque une standardisation des noms d'objets. Par le préfixe on sait rapidement le type d'objet produit.
P_ : paramètre
LST_COL_ : Liste construite à partir d'une colonne de table (le suffixe peut être le nom de la colonne extrait de la table)
STR_ : Variable de type texte
STR_Each : Pour construire une évaluation
INT_ : Variable de type entier
TBL_ : L'objet produit est une table
EVAL_ : On soumet une expression pour une évaluation via la fonction Expression.Evaluate
Source : Reste standard qui indique une source de données
Les préfixes peuvent être suivis de suffixes au choix afin de préciser le sens de la variable ou de l'objet comme par exemple TBL_AddedCustomClassif (Table comportant une nouvelle colonne)
CAS où la table est issue d'un fichier CSV - TBL_SRC_DATA_FLUX_2
La formule de rang sera à insérer également. Pour travailler sur cette table il suffit de modifier ce paramètre

Ayant eu dans un projet récent la nécessité d'identifier le TopN du nombre de flux par application et de les catégoriser en deux sortes, je vous partage les solutions que j'ai réalisé.
A vous de choisir celle qui vous convient le mieux selon la volumétrie que je n'ai pas testé.
Exemple de tableaux comportant des applications avec le nbr de flux qui ont été traités
Dans un 1er temps il a été nécessaire de déterminer le rang de chaque application comme ceci
via la formule : =EQUATION.RANG([@NbreFlux];[NbreFlux];1)
(occasion de découvrir EQUATION.RANG)
Voici le résultat pour chaque méthode
Tout cela passe par une liste de paramètres
Classification forte : Nom de la catégorie quand le rang (ordre) de l'item est dans le TopN (Top des applications) souhaité
Classification faible : Nom de la catégorie quand le rang (ordre) de l'item n'est pas dans le TopN (Top des applications) souhaité
Colonne quantification : Colonne permettant d'évaluer si le rang est dans le TopN
Colonne classification : Titre de la colonne qui va héberger la catégorie
Colonne item : Colonne de classement
Fichier CSV Flux : Nom du fichier .csv à importer en cas d'apport externe des données
Nombre d'applications à retenir pour le TopN :
pour le coup je n'ai pas utilisé de tableaux mais des noms de champs que je récupère dans PowerQuery pour les transformer à l'issue en table. Par ce biais voici une autre manière de gérer des paramètres que l'on passe à PowerQuery.
Liste des noms de champs
Environnement PowerQuery
Au premier coup d'oeil on aperçoit un début de standardisation des noms d'objets. Je me suis dit qu'il était temps de mettre cela en place depuis....mes nombreux codes en M.
La nomenclature me semble assez simple à comprendre, je passe donc sur ce point.
RECUPERATION DES NOMS DE CHAMPS
Pour chaque nom de champ le principe est le même - exemple :
Cas d'un type texte
PowerQuery:
let
Source = Excel.CurrentWorkbook(){[Name="ClassifForte"]}[Content],
TBL_ChangTypeColumn1 = Table.TransformColumnTypes(Source,{{"Column1", type text}}),
STR_ClassifForte = TBL_ChangTypeColumn1{0}[Column1]
in
STR_ClassifForteCas d'un type entier
PowerQuery:
let
Source = Excel.CurrentWorkbook(){[Name="TopApplis"]}[Content],
TBL_ChangTypeColumn1 = Table.TransformColumnTypes(Source,{{"Column1", Int64.Type}}),
INT_TopApplis = TBL_ChangTypeColumn1{0}[Column1]
in
INT_TopApplisPetite astuce pour regrouper les noms de paramètres commençant par PRM_ afin de les convertir dans une table TBL_PARAM
PowerQuery:
let
Source = #shared,
TBL_SHARED = Record.ToTable(Source),
TBL_PARAM = Table.SelectRows(TBL_SHARED, each Text.StartsWith([Name], "PRM_"))
in
TBL_PARAMLa colonne "Name" est filtrée par le préfixe PRM_ (d'où l'intérêt de standardiser les noms des objets).
Pour accéder à un paramètre une fonction fnGetParameters
PowerQuery:
let fnGetParameters =
(pName as any) =>
let
ParamSource = TBL_PARAM,
ParamRow = Table.SelectRows(ParamSource, each ([Name] = pName)),
Value=
if Table.IsEmpty(ParamRow)=true
then null
else Record.Field(ParamRow{0},"Value")
in
Value
in
fnGetParametersDésormais nous avons donc le choix, soit récupérer un paramètre via son de variable comme PRM_STR_ClassifFaible soit en utilisant la table de paramètre TBL_PARAM et la fonction fnGetParameters comme ceci P_STR_Quantif=fnGetParameters("PRM_STR_Quantif"),
Une version 5_1 récupère les paramètres via cette table.
RECUPERATION DES SOURCES DE DONNEES : TBL_SRC_DATA_FLUX_1
PowerQuery:
let
Source = Excel.CurrentWorkbook(){[Name=PRM_STR_NomTable]}[Content],
TBL_RemovedColumns = Table.RemoveColumns(Source,{PRM_STR_Ordre}),
TBL_ChangedTypeColumns = Table.TransformColumnTypes(TBL_RemovedColumns,{{PRM_STR_Item, type text}, {PRM_STR_Quantif, Int64.Type}}),
TBL_SortRows = Table.Sort(TBL_ChangedTypeColumns,{{PRM_STR_Quantif, Order.Descending}})
in
TBL_SortRowsNous avons ici utilisé directement la variable PRM_STR_NomTable.
Dans toutes les solutions on remarquera la gestion dynamique des noms de colonnes et l'utilisation de Expression.Evaluate qui permet de construire un code totalement paramétrable via une feuille Excel.
Version 1
Code:
let
Source = TBL_SRC_DATA_FLUX_1,
TBL_LST_KFR = Table.FirstN(Source,PRM_INT_TopApplis),
TBL_MergedQueries = Table.NestedJoin(Source,{PRM_STR_Quantif},TBL_LST_KFR,{PRM_STR_Quantif},"tmp__KFR",JoinKind.LeftOuter),
TBL_ExpandedKFR = Table.ExpandTableColumn(TBL_MergedQueries, "tmp__KFR", {PRM_STR_Item}, {"tmp__Columns"}),
TBL_AddCondColumn = Table.AddColumn(TBL_ExpandedKFR, PRM_STR_Classif, each if [tmp__Columns] = null then PRM_STR_ClassifFaible else PRM_STR_ClassifForte),
TBL_RemovedColumns = Table.RemoveColumns(TBL_AddCondColumn,{"tmp__Columns"}),
TBL_RemovedDuplicates = Table.Distinct(TBL_RemovedColumns, {PRM_STR_Item, PRM_STR_Quantif})
in
TBL_RemovedDuplicatesVersion 2
PowerQuery:
let
Source = TBL_SRC_DATA_FLUX_1,
FN_RankingList = (INT_Value) =>
let
STR_EachFn="each [" & PRM_STR_Quantif & "]>INT_Value",
EVAL_EachFn=Expression.Evaluate(STR_EachFn,[STR_Quantif=PRM_STR_Quantif, INT_Value=INT_Value]),
TBL_tmp= Table.RowCount(Table.SelectRows(Source, EVAL_EachFn)) + 1
in
TBL_tmp,
STR_EachRank="each FN_RankingList([" & PRM_STR_Quantif & "])",
EVAL_EachRank=Expression.Evaluate(STR_EachRank,[FN_RankingList=FN_RankingList]),
TBL_AddCustomClassif = Table.AddColumn(Source, PRM_STR_Ordre, EVAL_EachRank),
STR_Each="each if [" & PRM_STR_Ordre & "] <= INT_TopApplis then STR_ClassifForte else STR_ClassifFaible",
EVAL_Each=Expression.Evaluate(STR_Each,[STR_Ordre=PRM_STR_Ordre, INT_TopApplis=PRM_INT_TopApplis, STR_ClassifForte=PRM_STR_ClassifForte, STR_ClassifFaible=PRM_STR_ClassifFaible]),
TBL_AddCondColumn = Table.AddColumn(TBL_AddCustomClassif, PRM_STR_Classif, EVAL_Each),
TBL_RemoveColumns = Table.RemoveColumns(TBL_AddCondColumn,{PRM_STR_Ordre})
in
TBL_RemoveColumnsVersion 3
PowerQuery:
let
Source = TBL_SRC_DATA_FLUX_1,
LST_COL_Source = Table.Column(Source,PRM_STR_Quantif),
INT_N_Applis = LST_COL_Source{PRM_INT_TopApplis-1},
STR_Each="each if [" & PRM_STR_Quantif & "] >= INT_N_Applis then STR_ClassifForte else STR_ClassifFaible",
EVAL_Each=Expression.Evaluate(STR_Each, [STR_Quantif=PRM_STR_Quantif, INT_N_Applis=INT_N_Applis, STR_ClassifForte=PRM_STR_ClassifForte, STR_ClassifFaible=PRM_STR_ClassifFaible]),
TBL_AddCustom = Table.AddColumn(Source, PRM_STR_Classif, EVAL_Each)
in
TBL_AddCustomVersion 4
PowerQuery:
let
Source = TBL_SRC_DATA_FLUX_1,
TBL_AddIndex = Table.AddIndexColumn(Source, "tmp__Index", 1, 1),
TBL_GroupRows = Table.Group(TBL_AddIndex, {PRM_STR_Quantif}, {{PRM_STR_Ordre, each List.Min([tmp__Index]), type number}, {"tmp__Data", each _, type table}}),
TBL_ExpandData = Table.ExpandTableColumn(TBL_GroupRows, "tmp__Data", {PRM_STR_Item}, {PRM_STR_Item}),
STR_Each="each if [" & PRM_STR_Ordre & "] <= INT_TopApplis then STR_ClassifForte else STR_ClassifFaible",
EVAL_Each=Expression.Evaluate(STR_Each, [STR_Ordre=PRM_STR_Ordre, INT_TopApplis=PRM_INT_TopApplis, STR_ClassifForte=PRM_STR_ClassifForte, STR_ClassifFaible=PRM_STR_ClassifFaible]),
TBL_AddCondColumn = Table.AddColumn(TBL_ExpandData, PRM_STR_Classif, EVAL_Each),
TBL_RemoveColumns = Table.RemoveColumns(TBL_AddCondColumn,{PRM_STR_Ordre}),
TBL_ReorderColumns = Table.ReorderColumns(TBL_RemoveColumns,{PRM_STR_Item, PRM_STR_Quantif, PRM_STR_Classif})
in
TBL_ReorderColumnsAttention cette version n'affichera que les colonnes identifiées par les paramètres PRM_STR_Item, PRM_STR_Quantif, PRM_STR_Classif
Version 5
PowerQuery:
let
Source = TBL_SRC_DATA_FLUX_1,
LST_COL_Source = Table.Column(Source,PRM_STR_Quantif),
LST_TopListApplis = List.FirstN(LST_COL_Source,PRM_INT_TopApplis),
STR_Each="each if List.Contains(LST_TopListApplis,[" & PRM_STR_Quantif & "]) then STR_ClassifForte else STR_ClassifFaible",
EVAL_Each=Expression.Evaluate(STR_Each,[List.Contains=List.Contains, LST_TopListApplis =LST_TopListApplis, STR_ClassifForte=PRM_STR_ClassifForte, STR_ClassifFaible=PRM_STR_ClassifFaible]),
TBL_AddedCustomClassif = Table.AddColumn(Source, PRM_STR_Classif, EVAL_Each)
in
TBL_AddedCustomClassifVersion 5_1 avec la table des paramètres
PowerQuery:
let
Source = TBL_SRC_DATA_FLUX_1,
P_STR_Quantif=fnGetParameters("PRM_STR_Quantif"),
P_INT_TopApplis=fnGetParameters("PRM_INT_TopApplis"),
P_STR_ClassifForte=fnGetParameters("PRM_STR_ClassifForte"),
P_STR_ClassifFaible=fnGetParameters("PRM_STR_ClassifFaible"),
P_STR_Classif=fnGetParameters("PRM_STR_Classif"),
LST_COL_Source = Table.Column(Source,P_STR_Quantif),
LST_TopListApplis = List.FirstN(LST_COL_Source,P_INT_TopApplis),
STR_Each="each if List.Contains(LST_TopListApplis,[" & P_STR_Quantif & "]) then P_STR_ClassifForte else P_STR_ClassifFaible",
EVAL_Each=Expression.Evaluate(STR_Each,[List.Contains=List.Contains, LST_TopListApplis =LST_TopListApplis, P_STR_ClassifForte=P_STR_ClassifForte, P_STR_ClassifFaible=P_STR_ClassifFaible]),
TBL_AddedCustomClassif = Table.AddColumn(Source, P_STR_Classif, EVAL_Each)
in
TBL_AddedCustomClassifDans ce code comme les autres on remarque une standardisation des noms d'objets. Par le préfixe on sait rapidement le type d'objet produit.
P_ : paramètre
LST_COL_ : Liste construite à partir d'une colonne de table (le suffixe peut être le nom de la colonne extrait de la table)
STR_ : Variable de type texte
STR_Each : Pour construire une évaluation
INT_ : Variable de type entier
TBL_ : L'objet produit est une table
EVAL_ : On soumet une expression pour une évaluation via la fonction Expression.Evaluate
Source : Reste standard qui indique une source de données
Les préfixes peuvent être suivis de suffixes au choix afin de préciser le sens de la variable ou de l'objet comme par exemple TBL_AddedCustomClassif (Table comportant une nouvelle colonne)
CAS où la table est issue d'un fichier CSV - TBL_SRC_DATA_FLUX_2
PowerQuery:
let
P_STR_SourceCSVFlux=fnGetParameters("PRM_STR_SourceCSVFlux"),
Source = Csv.Document(File.Contents(P_STR_SourceCSVFlux),[Delimiter=";", Columns=3, Encoding=65001, QuoteStyle=QuoteStyle.None]),
TBL_Promote = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
TBL_ModifType = Table.TransformColumnTypes(TBL_Promote,{{"NbreFlux", Int64.Type}})
in
TBL_ModifTypeLa formule de rang sera à insérer également. Pour travailler sur cette table il suffit de modifier ce paramètre
Pièces jointes

Dernière édition: